AfriSenti-SemEval Shared Task 12
AfriSenti-SemEval: Sentiment Analysis for African Languages
Part of the 17th International Workshop on Semantic Evaluation
Please use the following BibTex entry to cite us if you use our dataset:
SemEval-2023 Task 12: Sentiment Analysis for African Languages (AfriSenti-SemEval).
@inproceedings
{muhammadSemEval2023,
title = {{SemEval-2023 Task 12: Sentiment Analysis for African Languages (AfriSenti-SemEval)}},
author = {Shamsuddeen Hassan Muhammad and Idris Abdulmumin and Seid Muhie Yimam and David Ifeoluwa Adelani and Ibrahim Sa'id Ahmad and Nedjma Ousidhoum and Abinew Ali Ayele and Saif M. Mohammad and Meriem Beloucif and Sebastian Ruder},
booktitle = {Proceedings of the 17th {{International Workshop}} on {{Semantic Evaluation}} ({{SemEval-2023}})},
publisher = {{Association for Computational Linguistics}},
year = {2023},
url = {https://arxiv.org/pdf/2304.06845.pdf}
}
AfriSenti: A Twitter Sentiment Analysis Benchmark for African Languages.
@misc
{muhammad2023afrisenti,
title={{AfriSenti: A Twitter Sentiment Analysis Benchmark for African Languages}},
author={Shamsuddeen Hassan Muhammad and Idris Abdulmumin and Abinew Ali Ayele and Nedjma Ousidhoum and David Ifeoluwa Adelani and Seid Muhie Yimam and Ibrahim Sa'id Ahmad and Meriem Beloucif and Saif M. Mohammad and Sebastian Ruder and Oumaima Hourrane and Pavel Brazdil and Felermino Dário Mário António Ali and Davis David and Salomey Osei and Bello Shehu Bello and Falalu Ibrahim and Tajuddeen Gwadabe and Samuel Rutunda and Tadesse Belay and Wendimu Baye Messelle and Hailu Beshada Balcha and Sisay Adugna Chala and Hagos Tesfahun Gebremichael and Bernard Opoku and Steven Arthur},
year={2023},
doi={10.48550/arXiv.2302.08956},
url={https://arxiv.org/pdf/2302.08956.pdf}
}
Contact organizers at: afrisenti-semeval-organizers@googlegroups.com
AfriSenti dataset is available at task's:GitHub repo
Motivation
Due to the widespread use of the Internet and social media platforms, most languages are becoming digitally available. This allows for various artificial intelligence (AI) applications that enable tasks such as sentiment analysis, machine translation and hateful content detection. According to UNESCO (2003), 30% of all living languages, around 2,058, are African languages. However, most of these languages do not have curated datasets for developing such AI applications. Recently, various individual and funded initiatives, such as the Lacuna Fund, have set out to reverse this trend and create such datasets for African languages. However, research is required to determine both the suitability of current natural language processing (NLP) techniques and the development of novel techniques to maximize the applications of such datasets.
There has been a growing interest in sentiment analysis which applies to many domains, including public health, commerce/business, art and literature, social sciences, neuroscience, and psychology (Mohammad, Saif M, 2022). Previous shared tasks on sentiment analysis include Mohammad, Saif M et al., (2018), Nakov et al., (2016), Pontiki et al., Ghosh et al., (2015), (2014), and so on. However, none of these tasks included African languages. Though Mohammad, Saif, et al. (2018) included standard Arabic, we focus on Arabic dialects from African countries: Algerian Arabic and Tunisian Arabizi. We believe SemEval is the right venue, due to its popularity and widespread acceptance, to carry out shared tasks for African languages to strengthen their further development.
In this shared task, we have covered 17 African languages, Hausa, Yoruba, Igbo, Nigerian Pidgin from Nigeria, Amharic, Tigrinya, and Oromo from Ethiopia, Swahili from Kenya and Tanzania, Algerian Arabic dialect from Algeria, Kinyarwanda from Rwanda, Twi from Ghana, Mozambique Portuguese from Mozambique and Moroccan Arabic/Darija from Morocco.
Task Overview
The AfriSenti-SemEval Shared Task 12 is based on a collection of Twitter datasets in 14 African languages for sentiment classification. It consists of three sub-tasks. Participants can select one or more sub-tasks depending on their preference. In each sub-task also, the participant may wish to participate in any number of languages as so wished.
Task A: Monolingual Sentiment Classification
Given training data in a target language, determine the polarity of a tweet in the target language (positive, negative, or neutral). If a tweet conveys both a positive and negative sentiment, whichever is the stronger sentiment should be chosen. This sub-task has 15 tracks:
Note: You are free to select one or more tracks in this sub-task.
- Track 1: Hausa
- Track 2: Yoruba
- Track 3: Igbo
- Track 4: Nigerian_Pidgin
- Track 5: Amharic
- Track 6: Algerian Arabic
- Track 7: Moroccan Arabic/Darija,
- Track 8: Swahili
- Track 9: Kinyarwanda
- Track 10: Twi
- Track 11: Mozambican Portuguese
- Track 12: Xitsonga (Mozambique Dialect)
- Track 13: Setswana (data to be released soon)
- Track 14: isiZulu (data to be released soon)
- Track 15: Xitsonga (South-African Dialect, to be released soon)
Note: Tweets in each language are code-mix. Read our NaijaSenti paper for more information.
Task B: Multilingual Sentiment Classification
Given combined training data from Task-A (Track 1 to 12), determine the polarity of a tweet in the target language (positive, negative, or neutral). This sub-task has only one track with 12 languages (Hausa, Yoruba, Igbo, Nigerian_Pidgin, Amharic, Algerian Arabic, Moroccan Arabic/Darija, Swahili, Kinyarwanda, Twi, Mozambican Portuguese, and Xitsonga(Mozambique Dialect)):
- Track 16: 12 languages in Task A
Task C: Zero-Shot Sentiment Classification
Given unlabelled tweets in two African languages (Tigrinya and Oromo), leverage any or all of the available training datasets (in Task:A ) to determine the sentiment of a tweet in the two target languages. This task has two (2) tracks.
Note: You are free to select one or more tracks in this sub-task.
- Track 17: Zero-Shot on Tigrinya
- Track 18: Zero-Shot on Oromo
Dataset Examples
The dataset involves tweets labeled with three sentiment classes (positive, negative, neutral) in 14 African languages. Each tweet is annotated by three annotators following the annotation guidelines in (Mohammad, Saif M, 2016). We use a form of majority vote to determine the sentiment of the tweet. See more in our paper (Muhammad et al., 2022, Yimam et al., 2020). Below is a sample dataset for the 4 Nigerian languges (Muhammad et al., 2022):
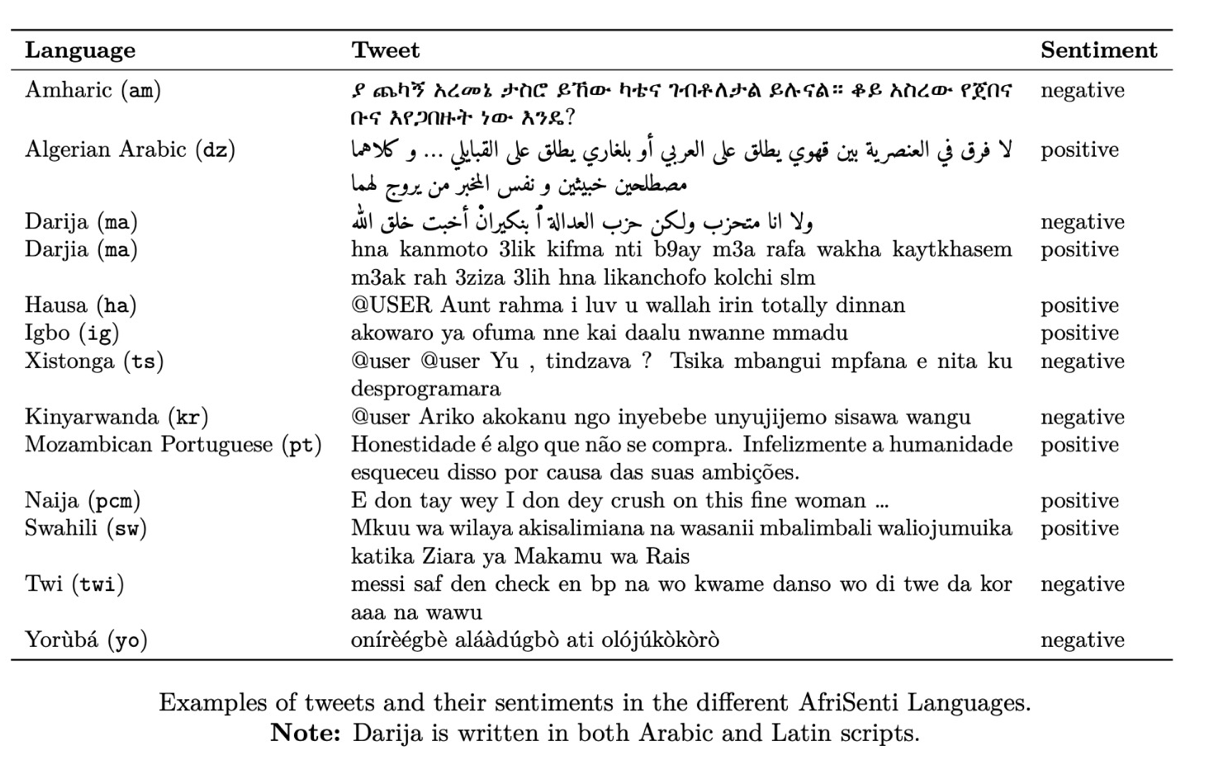
The datasets are available via the CodaLab competition website
Starter kit
We provide a Starter Kit on our GitHub Repo that can be used to crearte a baseline system.
Why Participate ?
- Promote NLP research involving African languages,
- Opportunity to write a system-description paper that describes their system, resources used, results, and analysis.
- Stand a chance to win an award.
- Opportunity to network with renowned experts in the AI and NLP community.
Resources on Paper Submission
Important Dates
| Descriptions | Deadlines |
|---|---|
| Sample Data Ready | |
| Training Data Ready | |
| Evaluation Start | |
| Evaluation End | |
| System Description Paper Due | 28th February 2023 |
| Notification to authors | 31 March 2023 |
| Camera ready due | 21 April 2023 |
| SemEval workshop 2023 | 13-14 July 2023 (co-located with ACL-2023 in Toronto, Canada |
All deadlines are 23:59 UTC-12 ("anywhere on Earth").
Communication
- Join Task Mailing List
- Join Task Slack Channel to communicate with the organizers.
- Contact Organizers: afrisenti-semeval-organizers@googlegroups.com
Previous Shared Tasks
-
Shared tasks in English:SemEval-2017,SemEval-2016,SemEval-2015,SemEval-2014,SemEval-2013
-
Shared tasks in Spanish TASS-2017,TASS-2016,TASS-2015,TASS-2014,TASS-2013,TASS-2012.
References
- UNESCO. 2003. Sharing the world of difference. UNESCO.
- Mohammad, Saif M. "Ethics sheet for automatic emotion recognition and sentiment analysis." Computational Linguistics 48.2 (2022): 239-278.
- Preslav Nakov, Sara Rosenthal, Svetlana Kiritchenko, Saif M Mohammad, Zornitsa Kozareva, Alan Ritter, Veselin Stoyanov, and Xiaodan Zhu. 2016. Developing a successful SemEval task in sentiment analysis of twitter and other social media texts. Language Resources and Evaluation, 50(1):35–65.
- Mohammad, Saif, et al. "Semeval-2018 task 1: Affect in tweets." Proceedings of the 12th international workshop on semantic evaluation. 2018.
- Maria Pontiki, Dimitris Galanis, John Pavlopoulos, Harris Papageorgiou, Ion Androutsopoulos, Suresh Manandhar. 2014: SemEval-2014 Task 4: Aspect Based Sentiment Analysis, Dublin, Ireland
- Saif Mohammad. 2016. A Practical Guide to Sentiment Annotation: Challenges and Solutions. In Proceedings of the 7th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, pages 174–179, San Diego, California. Association for Computational Linguistics.
- Aniruddha Ghosh, Guofu Li, Tony Veale, Paolo Rosso, Ekaterina Shutova, John Barnden, Antonio Reyes. 2015: SemEval-2015 Task 11: Sentiment Analysis of Figurative Language in Twitter, Denver, Colorado
- Shamsuddeen Hassan Muhammad, David Ifeoluwa Adelani, Sebastian Ruder, Ibrahim Said Ahmad, Idris Abdulmumin, Bello Shehu Bello, Monojit Choudhury, Chris Chinenye Emezue, Saheed Salahudeen Abdullahi, Anuoluwapo Aremu, Alipio Jeorge, Pavel Brazdil. 2022, NaijaSenti: A Nigerian Twitter Sentiment Corpus for Multilingual Sentiment Analysis, Marseille, France
- Seid Muhie Yimam, Hizkiel Mitiku Alemayehu, Abinew Ayele, Chris Biemann. 2020: Exploring Amharic Sentiment Analysis from Social Media Texts: Building Annotation Tools and Classification Models, Barcelona, Spain (Online)
Funding Acknowledgements
This prize award for this shared task was generously supported by a grant from Lacuna Fund.